Last Monday afternoon, a link to CodinGame was posted on Reddit. It gained a lot of success and resulted in what is called a hug of death. Our platform went down for 2 hours because of the overwhelming amount of new visitors.
Internet is Beautiful
This was so far a normal day. We were working on the last preparations for the next multiplayer coding contest Hypersonic to be held this Saturday. Around 2pm, Nico, our CTO, shouted that we were suddenly receiving a lot of traffic.
A link to our starting page had been posted on the subreddit /r/InternetIsBeautiful under the title “Learn to code writing a game”. The traffic was already 10 times higher than usual and we were rejoicing.

The post on Reddit
After a few minutes watching the incoming traffic grow more and more, we began to notice some lags…
When will it stop? Can we support the load?
From Excitement to Panic
After some quick monitoring, we realized the CPU of the database server was already capped. We decided to multiply the capacity of our RDS (Amazon Relational Database Service) by 4 on AWS. It took 30 minutes at the end of which it interrupted the service completely. We had no choice.
After that change, the server was able to take in a lot more load, lags came back again pretty soon, when some other point of the architecture started to fail too. Now the front-end servers were failing.
The CodinGame platform normally uses two application servers hosted on EC2, behind a load balancer. So we tried scaling up by doubling that number (we eventually reached 6 servers in the end), but some of them started to crash. We tried relaunching them, to see them fail again after a short time.
The platform was becoming barely usable. What a waste, all this traffic to a dead/lagging site…
Reddit had put CodinGame to its knees.
Crisis Management
While activity on our social media channels started to increase, the CodinGame chat was buzzing with questions. The community regulars were doing their best welcoming newcomers.
The chat server was also under heavy load and wouldn’t accept new users (more on this later). Forum didn’t last long either. We took the opportunity to offer an AMA (ask me anything) in the comments of the Reddit thread.
At the same time, a Twitch streamer was desperately waiting to do a Clash of Code session. Things were looking bad and everyone was preoccupied. Reddit finally tagged the post with “Hug of Death” so visitors didn’t end on a dead site.
The End of the Tunnel
After two long hours, we managed to get the servers back and running, and we asked the Reddit moderators to bring back the thread. Traffic came back as a wave as the thread was reposted on Hacker News and other tech news sites. And lags again. Something was taking down our servers and we couldn’t find what. Finally, we put in place a script that would reboot a server each time it failed so we maintain the service over the night.
Reddit's hug of death on CodinGame, it reminded me this moment from Silicon Valley: https://t.co/Xwp4Q8FVfV Still on Reddit frontpage!
— Maxime Chéramy (@MaximeCheramy) September 19, 2016
On Tuesday afternoon, when things had calmed down, we took the time to come back on what had happened. Traffic had been crazy: we got as many new users in one day as during the last two months. There had been technical failures. Understandable failures but to be taken care of.
Post-Mortem – What Went Wrong
1) The main bottleneck of the CodinGame platform is the RDS database. We centralize every information on CodinGame there, all tangled. We cannot distribute the database without setting up separate servers splitting users, for instance by region (America, Europe, Asia). This is the major scaling issue.
Solution: the short term action we’ll take is to investigate caching solutions, distributed caches between our application servers.
2) The second issue we’re currently following up is a memory leak on the application servers. This bug occurs when a server is under heavy load and eventually leads to a crash.
Solution: track the bug, kill the bug.
3) We host The CodinGame forum on a really small machine. It is poorly integrated on the platform through an iframe so that every user on any page of the site sends an SSO authentication request to the forum. The number of queries that were sent to this instance capped the CPU, and just like that, the forum was no more.
Solution: Better integrate SSO between the website and the forum to avoid unnecessary requests. Migrate the forum on a tougher machine.
4) This very blog crashed, simply because it was… hosted on the same machine as the forum, that maxed out the CPU.
Solution: Separate applications in different containers/machines.
5) The CodinGame chat server did exactly what it was expected to do. It failed under heavy load. It uses XMPP over WebSocket, with a custom client built on top of stanza.io, and a back-end built with Prosody. Prosody is a really cool back-end built with lua. But it has the slightest problem: it is single-threaded and non-distributable. So, as expected, the server process quickly reached 100% of a single CPU core and started to lag badly and act erratically. It didn’t crash, but wouldn’t take in new users.
Solution: Switch our back-end solution to a scalable one, such as eJabberd or MongooseIM.
6) Last point of failure in this real world scalability test: the push server. We use a websocket connection to push data to the client, triggering diverse events (notifications, mostly). This server had a limitation of open file descriptors, arbitrarily set to 10K. We set it to 100K and it started working again, accepting up to 60K simultaneous connections (this is the best estimation we have of the number of open tabs at that moment) before it went night-night.
Solution: This is an Embarrassingly Parallel Problem, and it should have been a scalable pool of servers behind a load balancer from the beginning.
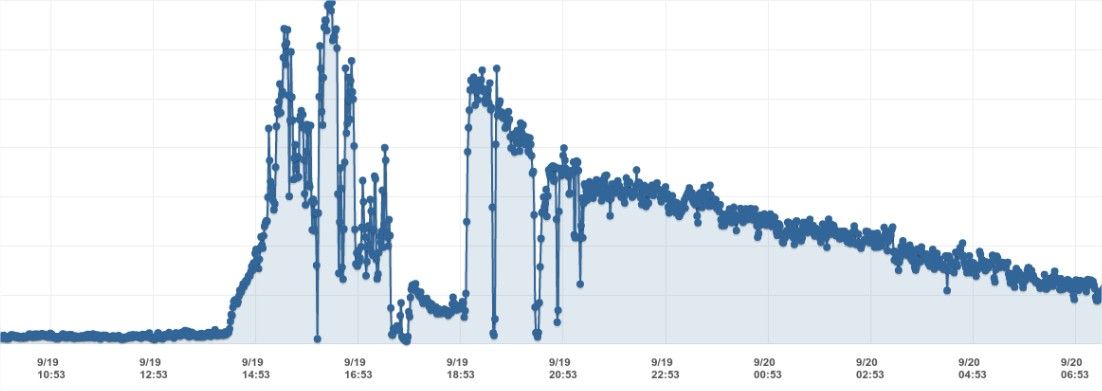
Impact of Reddit on the traffic
We took a blow, but we’re back on our feet, stronger than ever. We’ll be happy to answer any question you might have about this special event. Don’t hesitate!
Welcome to all the new users!