I’m really happy I managed to reach the 3rd rank at the Coders Strikes Back contest. It was a really great competition with a nice game. Here below is a summary of my strategy.

Use the force!
Core Algorithm: Evolutionary Trajectory Optimization
Genetic Algorithm
The core of the AI is based on a genetic algorithm. There are a lot of resources on the Internet to understand this class of algorithm, but here are the basic requirements to implement one:
- Define basic individuals with a behavior that can be described with a set of numeric parameters. In my case, an individual is a sequence of [thrust; angle] instructions for the next six turns; plus a turn at which the shield is activated.
- Implement a fitness function which describes how good the individual behaves in its environment. In my case, the fitness calculation is based on a physics engine which simulates 6 game turns and evaluates the final state.
- Mutate/crossover/select individuals from your population.
Example of Genome Encoding for an Evolutionary Entity
Turn 0 | Turn 1 | Turn 2 | Turn 3 | Turn 5 | Turn 6 | |
Angle picked randomly in [-40; +40], then bounded in [-18;18] | -18 | -18 | -18 | -10 | 0 | 0 |
Thrust picked randomly in [-100; +400], then bounded in [0;200] | 0 | 0 | 50 | 200 | 200 | 200 |
Shield Activation picked randomly in [0; 8] determines the turn when the shield is activated | 2 |
Subtleties of the Evaluation Function
The evaluation function presented in this paragraph only involves a runner pod which wants to end the race as soon as possible. I describe a more complete evaluation function with a blocker pod later below.
The parameters taken into account are the following:
- If the race is finished, the time until arrival
- If the race is not finished, the number of checkpoints left + distance until the next checkpoint. This distance is taken between the pod and an arbitrarily defined entry point, as shown on the figure below.
- A late addition was with a small factor, the angle between the opponent blocker and my runner’s next checkpoint, as seen by my runner.
The distance until the next checkpoint is calculated between the pod and an arbitrary point inside the checkpoint.
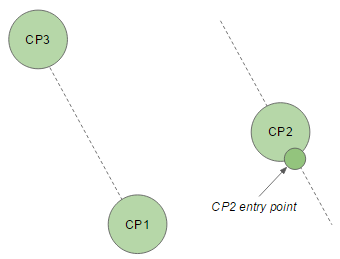
Definition of a checkpoint’s entry point
The definition of the entry point was used to counteract the pod’s tendency to settle in sub-optimal trajectories as shown in the figure below:
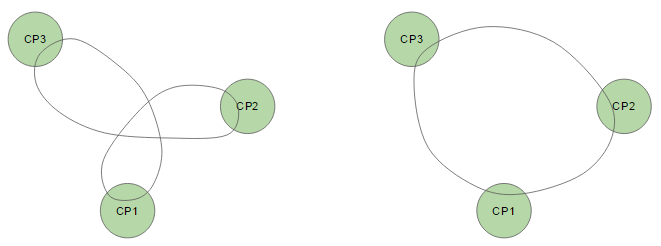
Two types of trajectories found by the pod (suboptimal/optimal)
Unfortunately, evaluating the factors above after six turns of simulation requires having a good prediction of the opponent’s movements. In order to account for uncertainties in what happens in the future, the evaluation is conducted twice:
- After one turn of simulation with a 10% weight
- After six turns of simulation with a 90% weight
Twenty-four hours before the end of the contest, this simple AI with only two runners and no collision simulation was ranked 15th on the leaderboard. When approaching such a contest, a strong base is required before additional features are implemented.
Runner/Chaser Implementation
Based on the simulation/evolution component described above, a more complex runner/chaser behavior is devised.
General Behavior
Repeat each turn:
- Define all pods’ roles: my runner, my blocker, the opponent’s runner and the opponent’s blocker.
- During 12ms, use the evolutionary algorithm to predict a trajectory for the opponent’s runner.
- During 12ms, use the evolutionary algorithm to predict a trajectory for the opponent’s blocker. The simulation is done with my runner using a very basic movement behavior.
- Inject the two trajectories predicted in the game simulator: they will be used for the next simulation.
- Define a “waiting checkpoint” for my blocker bot to wait for the opponent’s runner.
- During 116ms, use the evolutionary algorithm to define a combined trajectory for my two pods. This combination means that both the pods’ genomes are evolved at the same time. This is the main feature that allows the algorithm to find a cooperative behavior between the pods.
During these 116ms, some simulations will involve collisions with the opponent’s pods. When a collision is detected, the fixed trajectories calculated beforehand are discarded: control of the opponent’s bot switches to a basic movement behavior.
Combined Evaluation Function
The behavior defined above involves using a more complex evaluation function to calculate the evolutionary entities’ fitness.
The evaluation is a combination of a runner evaluation and a blocker evaluation. The basic concept of the runner evaluation function is not modified, as described in part 1).
The blocker part of the evaluation function gives a bonus to:
- If I am not at risk to timeout:
- Reducing the opponent’s runner evaluation
- Maintaining my blocker’s angle in the direction where the opponent’s runner is (maintain eyes on target)
- Minimizing the angle under which the opponent’s runner sees his next checkpoint and my blocker (stay between him and his next checkpoint)
- Minimize the blocker’s distance to his waiting point. (wait for the opponent in front of his next checkpoint).
- If I am at risk to timeout:
- The blocker uses the same evaluation function as a runner to take his next checkpoint and reset the timer.
All the factors above are weighted according to their order of importance. For example, the “wait for the opponent in front of its next checkpoint” has of low priority compared to pushing it out of its path.
I received many questions during the contest asking how my runner would become berserk and act like a second blocker. There is no magic in there: it is simply not specified in the evaluation function what pod should be used to reduce the opponent’s runner evaluation. The blocker evaluation function can be over-weighted or under-weighted to change my runner bot’s tendency to have a blocker behavior.
I had a lot of fun during the last three days of the contest uploading a version of the AI with a behavior where the runner wants to block a hundred times more than it wants to advance. In the final release, I brought this value down to 1.5.
Conclusion
The contest was challenging and interesting.
Positives
- The games were 1v1. Games with more than two players generally evolve into a race towards greediness, and the top bots’ final strategies have (carefully designed) holes, that they hope other greedy opponents won’t exploit. Under that light, Coders Strike Back is much better designed than Back to the Code for example.
- Many approaches seemed viable, as seen in the forum (evolutionary algorithms, beam search, minimax, basic heuristics, or even neural networks for some).
- “Easy to participate, hard to master”: a great game for everybody!
Negatives
- Incomplete description of the rules and physics engine. Either the game is to reverse engineer the simulation engine, or the game is to program the best AI. It is particularly disappointing to spend 24 hours “debugging” a local simulation engine before understanding there is a hidden minimum-impulse on collisions.
- The ranking system. TrueSkill is set up to “forget” old matches from a player, as it is expected that a human player’s level will evolve with time. This is not the case for an AI: the rankings should be able to stabilize over time without the feeling that luck is involved in the process.