I’m very happy I won the Smash the Code contest. I recently reached the 3rd position of the Coders Strike Back contest, and already shared how I implemented a genetic algorithm here on the blog. Here below is the strategy that made me win Smash the Code.
Core Algorithm: Finding the Best Combos
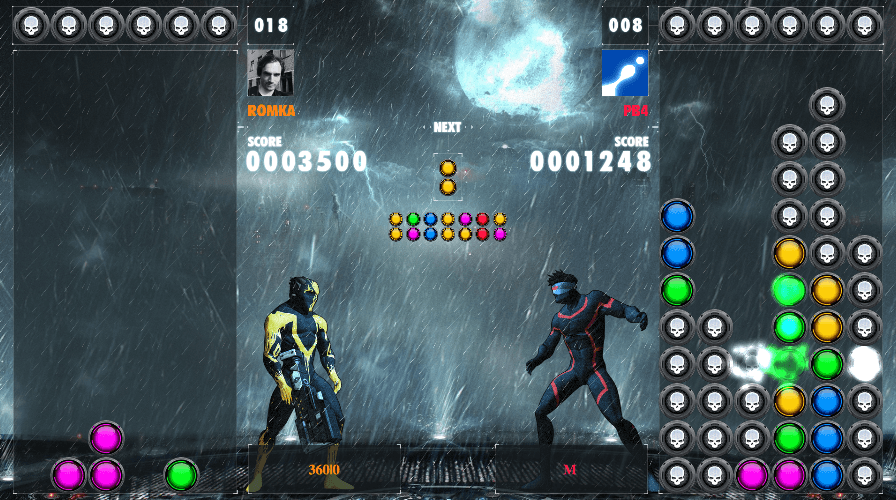
Finding the best combos was key
Initial Approach
This game has a medium branching factor of 22 placement possibilities each turn. Future game pieces are known for the next 8 turns. An exhaustive search for the placement of those 8 pieces would require 22^8 simulations of the game board: this number is too impractical during a 100ms time frame. At most, an exhaustive search can be expected to go as deep as depth 4, missing on potentially great combos.
I analyzed a few games at the beginning of the challenge, and made a few observations:
- Good combos involve long-term preparation with planning more than 4 pieces in advance. This is particularly important at the beginning of the game when placing the very first pieces.
- How many times did you see two AIs play different sequences and end up with the same combo? A lot. There are numerous ways to prepare a good combo: if you can find one, you don’t need to find all the other ones.
Those two observations suggest that it is very important to look far ahead in the future. And that given the huge number of ways to prepare a good combo, it is acceptable not to explore all possibilities exhaustively. The two ways I considered were:
- Start with an exhaustive search and prune the tree as you go deeper (beam search)
- Use a stochastic algorithm to explore the possibilities in a somewhat random manner. (Pure Monte Carlo, Simulated Annealing, Genetic Algorithm, MCTS with UCT, …)
Unable to find a reliable and computationally cheap heuristic to perform a beam search, I settled on the stochastic approach.
Stochastic Algorithms
Pure Monte Carlo, Simulated Annealing, Genetic Algorithm, MCTS with UCT: all are stochastic optimization algorithms. In essence, they share the same principle:
Try something at random. Was it good?
Yes: save it.
No: try something else
The point on which they differ is how “try something else” is defined. Pure Monte Carlo is completely random, whereas the other algorithms implement ways to learn from previous mistakes in order to converge faster towards an optimum.
Already familiar with genetic algorithms, I decided to settle on this approach to find the best combo. There is a lot of good reading material available on that topic, some of it even on CodinGame’s forum! (see for example Magus’ article on Coders Strike Back).
In Smash the Code, defining a genome is straightforward: it is a set of 8 integers between 0 and 21, representing the placement of the next 8 game pieces.
Heuristics to Identify a Good Combo
Much less straightforward is the definition of a good combo. Should you prefer dropping 5 skulls on your opponent 3 turns in the future, or 8 skulls 4 turns in the future? A score calculation is made after simulating a sequence of 8 moves.
Here is the basic breakdown of the ordering rules used in my algorithm.
- If I lose at the end of the sequence, lose as late as possible.
- If I dropped more than N skulls on the opponent during the sequence, drop them as soon as possible.
- Otherwise, maximize a value calculated as the sum of the following features :
Feature | Reasoning |
Discounted score sum of (scores * (0.8^turn)) | Make sure that short-term combo options are kept available |
Board arrangement quality (number of pairs, number of triples, number of skulls, number of open spaces, and various combinations of those) | Prepare for potentially big combos beyond the 8 pieces horizon |
At this point, here are a few remarks I’d like to make:
- In the “board arrangement quality” indicator, if the only features used are positive (bonus for this, bonus for that…), this is an incentive for the AI to fill the board. Consider it this way: an empty board is worth 0. A full board with only a single pair is worth a positive number of points. Your AI will prefer the full board with only a single pair. Is it really what you want? Don’t forget to add negative features to help your AI identify correctly the best situations.
- The discounted score is only taken into account if no combo better than N skulls was found.
- The behavior of the bot can be tuned from “aggressive” (low N, low discount factor, low weight for the board arrangement quality) to “longer-term oriented” (high N, high discount, medium weight for the board arrangement quality. This was used extensively to predict the opponent’s behavior (see below)
- 4 days before the end of the contest, the simple AI described above was ranked #1 in the leaderboard.
Advanced Algorithm: Countering the Opponent’s Combos
Handling the opponent
Preparing combos on your side of the board is a good strategy. However, if the opponent sends skulls on your board before you can trigger your combo, all the hard work was done for nothing.
A basic way to handle this was already described above: if you only target smaller combos, there are limited chances that your opponent can block you. But then, why wouldn’t you wait for two more turns to end the game quickly with a huge combo?
To take the opponent into account, I used a more complex approach based on the concept of a scenario. A scenario is defined as the prediction of the number of skulls that will drop on your board for each of the next 8 turns.
The idea is to sequentially evaluate what scenario should be expected from each player, and act accordingly. In the end, I settled for a 3-step approach described in the table below :
Step | Time allocated | Player simulated | Scenario | Behavior | Reasoning |
1 | 20ms | Me | No skulls dropped | Long-term builder | Can I prepare game-ending combos? |
2 | 20ms | Opponent | Best for me playing at step 1 | Short-term defensive | The opponent will try to prevent me from using those combos. |
3 | 55ms | Me | Best for the opponent playing at step 2 | Balanced | Can I still make a game-ending combo? Or should I play short-term too? |
Opponent Prediction can Make You Worse
Direct application of this method can easily lead to bad play. The reason behind this is that an AI becomes afraid of what the opponent does, and acts accordingly by planning for smaller combos.
- If the opponent has a more long-term behavior than what you planned, you are effectively aiming for smaller combos than him and will lose.
- If the opponent has a more aggressive behavior than what you planned, you’ll always be one step behind.
- If the opponent has a well-balanced behavior, your main “search time” is down to 55ms against the 100ms available to him.
Variations on this Method
At some point during the contest, I repeated step 2 several times with an aggressive, a balanced and a long-term opponent behavior to come up with 3 different likely scenarios. Then step 3 was modified to find the best solution on average in those 3 scenarios. I believe this approach makes the most sense, but its computational cost was too high and I had to scale things down.
At another point in the contest, I only used step 2 and 3. This resulted in a better behavior against top 50 AIs, but worse against top 5 AIs. I was aiming for top 5 and tuned my AI accordingly.
It took a lot of work to tune all the behaviors to a point where trying to predict the opponent’s move actually resulted in better play.
Gains from Predicting the Opponent’s Behavior
Based on tests during the contest, I would say that this complex approach to handle the opponent’s move was only worth 1 or 2 points in the rankings. This comes in big contrast with other contests (Poker Chip Race: opponent prediction is worth 10 points. Coders Strike Back: good opponent prediction is worth > 10 points).
I believe the interactions with the opponent were too limited and should be more prevalent in future contests.
Miscellaneous
On Game Theory and Simultaneous Games
Simultaneous games such as Smash the Code are very complex to approach from a game theory point of view. Here is a reference article on Wikipedia on the prisoner’s dilemma. It is an example of a very simple game: only 2 options are available to you and your opponent, limited to 1-ply depth, perfect knowledge of the rewards gained in all outcomes. As seen by the length of the article, the analysis of such a game is already very complex!
Unless every player on CodinGame can find a Nash equilibrium for simultaneous games (which will never happen), the winning strategy will always be to assume that your opponent plays sub-optimally.
The objective switches from “being as good as possible at the game” to “being good against the players I am faced with”. This is the core reason why we see cycles appear where player A beats player B, player B beats player C and player C beats player A.
A comment on the ranking system at this point: the player ranked #1 on the leaderboard plays more than 50% of his matches against the player ranked #2. This fact and the presence of cycles with player A>B>C>A can make the rankings unrepresentative of the actual strength of an AI. I suggest that ranking matches are picked somewhat more randomly than what is currently done.
A Few Figures on Code Performance
During the 100ms allocated to one turn, I was able to make up to one million simulations of one move (or 125k playouts of 8 moves). That number decreased as the board filled up, but never went below 400k simulations.
Credits to Jeff06 who shared with me (among many other things) his lightning-fast BFS code from The Great Escape: it was a great starting point to build upon!
Conclusion
The contest was challenging and interesting.
Positives
- 1v1 games. Those are, by far, the best. Thank you CodinGame for leaving aside the 1v1v1 format!
- The league system: A great addition! The league system also provides a reference point to track global improvements of the AIs. There is no need anymore to submit an “old” AI to find out how much your “new” AI has improved!
- The Last battles page. More readable than before, with more information conveyed at the same time. Maybe add icons when a loss happened due to a crash or a timeout?
- This might come as a negative to some, but the contest weighted raw code performance very strongly. As a non-programmer who learns C++ during CodinGame contests, my previous contest participations were hindered by sub-par code in raw execution speed. It is an incredibly satisfying achievement for me to say that this time I was at least equal to people that I look up to.
Negatives
- Incomplete input: Players were not given complete input about the game state. This point was brought up several times on the forums. I understand it is more a mistake than a design feature and I am sure this will not be an issue in the upcoming contests.
- The relatively random outcome of single matches. In Smash the Code, even a 55% win rate against a player is hard to achieve. I can’t pinpoint exactly why, but the range of skills displayed by the AIs seems smaller than in other contests.
- Low readability of the game state: Is someone preparing for a big combo? When watching a replay, I have absolutely no idea what is happening. I don’t know how it could be done cheaply, but would it help if the CG game engine displays the best combo available for the players at a 1,2,3,4 and 5 turns horizon?
- Ranking system: The system is very good to have an idea of your approximate level during the competition. It is not suited to rank people precisely at the end of the contest: the effect of fluctuations is very strong. More on that topic on this thread of the forum.
If you’re interested in other players’ AIs, there is a dedicated post here.